1、并发编程理论
本章节中同步和异步阻塞和非阻塞较难理解, 只做了浅显的介绍, 如果需要深层次理解可以参考 怎样理解阻塞非阻塞与同步异步的区别? 问题下的回答
1-1 CPU 密集型与 I/O 密集型
CPU 密集型 (CPU-bound):
- 在执行数据处理、科学计算等任务时, CPU 的资源被大量使用, 这个任务属于 CPU-bound
I/O 密集型 (I/O-bound):
- 在进行交互操作、Web 应用等任务时, 大部分时间 CPU 都在等待 I/O (输入/输出) 任务的数据时, 这个任务属于 I/O-bound
1-2 并发与并行
并发 (Concurency): 代表计算机可以同时执行多个任务
- 单核处理器: 计算机通过分配时间片的方式, 让多个任务交替运行, 这个过程被称为进程或是线程的上下文切换 (context switching)
并行 (Parallelism): 代表计算机同时处理多个任务
- 多核处理器: 计算机调用多个处理器, 同时处理多个任务, 这种情况称为并行
1-3 进程与线程
进程 (Process):
- 进程是操作系统中的一个基本概念, 它包含运行一个程序所需要的资源, 一个正在运行的应用程序在操作系统中被视为一个线程
- 进程之间是相对的, 一个进程无法访问另一个进程的数据 (除非使用分布式计算方式), 一个进程的失败同样不会影响其他进程
- 操作系统利进程将工作区划分为多个独立的区域, 进程作为程序的运行边界
- 简单来说一个进程就相当于一个正在运行的应用程序, 是应用程序的一次动态执行过程
线程 (Thread):
- 一个进程中可能存在一个或多个线程, 现成是操作系统分配处理器时间的基本单元, 可能有多个线程在同时执行代码
- 在进程入口执行的一个线程被称为程序的主线程
- 线程主要由 CPU 寄存器、调用栈和线程本低存储器 (Thread Local Storage, TLS) 组成
- CPU 寄存器主要记录当前执行线程的状态
- 调用栈主要用于维护线程所调用的内存与数据
- TLS 主要用于存放线程的状态信息
- 线程本身不是一个计算机硬件的功能, 而是操作系统提供的一种逻辑功能
- 多线程本质上是进程中一段并发执行的代码, 需要操作系统提供 CPU 资源来运行和调度
进程和线程的区别
- 进程拥有独立的地址空间, 进程崩溃后, 在保护模式下不会对其他进程产生影响
- 线程是一个进程中的不同执行路径, 线程有自己的堆栈和局部变量, 却没有自己单独的地址空间, 一个线程崩溃会导致整个进程结束
- 多进程的程序要比多线程的程序更安全可靠, 但在切换进程的时候, 资源耗费会比多线程更大, 效率相对较差
- 多线程的程序有自己的局部变量, 对于需要共享局部变量的并发操作, 只能使用多线程实现
1-4 同步与异步
同步和异步关注的是消息通信机制 (synchronous communication / asynchronous communication)
同步 (Synchronous):
- “调用者” 主动发送一个 “调用”, 在没有得到结果之前, 这个调用就不会返回, 但是一旦调用返回, 就能直接获得返回值
- 同步相当于是由 “调用者” 主动等待这个 “调用” 的结果
异步 (Asynchronous):
- 与同步相反, 在 “调用” 发出后, 这个调用直接返回了, 此时并没有返回值
- 当一个异步过程的 “调用” 发出后, 调用者不会立即获得返回结果, 而是在 “调用” 发出后, “被调用者” 通过状态, 通知, 来告知 “调用者”, 或者通过 “回调函数” 处理这个调用
一个例子: 假设我需要知道我的卡里还剩下多少钱
同步通信机制下: 我 (“调用者”) 打电话给银行询问客服 (发送 “调用”), 客服告知正在查询, 并让我稍作等待, 于是我在通信的过程进行了等待, 稍后客服告知了我查询结果 (返回 “调用” 结果)
异步通信机制下: 我 (“调用者”) 打电话给银行询问客服 (发送 “调用”), 客服告知正在查询并挂断了电话 (不返回结果, 返回状态), 在等待结果期间, 我可以去做其他事情, 在查询完成后, 客服主动打电话告知我结果 (通知并”回调” 结果)
- 同步和异步实际上代表的是两种不同的编程模型, 可以通过多种方式来实现
1-5 阻塞与非阻塞
阻塞和非阻塞描述的是程序在等待 “调用” 结果 (消息、返回值) 时的状态
阻塞调用是指在调用结果返回之前, 当前线程会被挂起, 调用线程只有在得到结果之后才会返回。
非阻塞调用指的是不能立刻得到结果之前, 该调用不会则当前线程
依然假设我需要知道我卡里还剩多少钱
阻塞调用: 在客服告诉我结果之前, 我会把自己 “挂起” 直到客服告诉我结果
非阻塞调用: 无论客服是否告诉我结果, 我都会继续做其他事情, 并隔一段时间检查一下客服是否有返回结果
(这里的阻塞与非阻塞和同步异步无关, 跟客服用何种方式告知你返回结果也无关)
补充说明
多线程 (Multi threading):
- 多线程编程可以是实现异步的一种方式 (但并不是唯一), 创建多个线程一起运行
- (Python 中就可以使用
async和await函数实现异步)
- (Python 中就可以使用
- 在多核的环境下, 每个线程都会被分配到独立的核心上运行从而实现 “并行”
- 在单核的环境下, 操作系统会通过分配时间片的方式执行这些线程, 但也是 “并发” 地在执行
- 单核 CPU 使用多线程主要应用在 IO 密集型任务时防止阻塞
- Reference: 对于单核cpu而言,开多线程的目的难倒只能是为了防止阻塞么?
- I/O 密集型任务更加适合使用异步编程方式, 不一定适合多线程
- 线程本身会占用内存, 切换线程也会占用资源
- 计算量密集的应用程序通常都适合使用多线程计算
- Reference: https://www.youtube.com/watch?v=I3E4MHTpABA
2、多线程 threading 模块
2-1 创建和启动线程
threading.Thread 创建线程
- 使用
import threading导入多线程模块 - 使用
thread_obj = threading.Thread(target=函数名称, args=(参数1, 参数2))来定义多线程对象args只有一个参数时, 需要在第一个参数后跟上逗号,
- 使用
thread_obj.start()启动一个线程- 可以同时启动多个线程
1 | import threading |
重写 Thread 父类 run 方法实现多线程
- 重写的多线程需要继承父类的
__init__成员 - 重写 run 方法
1 | import threading |
计算子线程执行时间
- 在执行
sleep函数时将不会占用 CPU 资源, 程序将会被挂起 - 每个线程都可以添加一个
join()方法等待线程结束, 当所有join()等待的线程都结束后, 主线程才会继续运行
1 | import threading |
1 | # Output |
统计当前活跃的线程数
主线程比子线程执行要快, 当主线程执行 active_count() (返回当前活动的线程总数) 时, 其他子线程都没执行完毕, 可以在主线程使用 threading.active_count() 统计所有活跃线程的数量
1 | import threading |
1 | # Output |
守护进程
- 实例化时候指定
daemon=True可以将线程设置为守护进程, 当主线程结束时, 守护进程也会结束 - 守护线程必须在线程
start()方法之前设置
1 | import threading |
1 | # Output |
2-2 线程安全
GIL 全局解释器锁
GIL 锁的定义
全局解释器锁(英语:Global Interpreter Lock,缩写GIL)
是计算机程序设计语言解释器用于同步线程的一种机制,它使得任何时刻仅有一个线程在执行。
即便在多核心处理器上,使用GL的解释器也只允许同一时间执行一个线程。
在 Python 中即使多 CPU ,每个 CPU 的进程中的线程,同一时刻只能执行一个线程
而在其他大部分编程语言中是任意一个 “时刻” 一个cpu执行一个线程,多个cpu可以同时刻执行多个线程
为何会有 GIL ?
Python 设计初期, 为了规避多线程之间数据的完整性和状态同步问题, 引入了 GIL 这个概念, 发展至今大部分第三方库都依赖 GIL, 导致无法去除
如何规避 GIL 带来的问题
多线程 threading 机制依然是有用的,用于IO密集型计算, 因为在 I/O (read, write, send, recv, etc) 期间,线程会释放GIL, 实现CPU和IO的并行, 因此多线程用于IO密集型计算依然可以大幅提升速度, 但是多线程用于CPU密集型计算时,只会更加拖慢速度
使用 multiprocessing 的多进程机制实现并行计算、利用多核CPU优势, 为了应对GIL的问题,Python提供了multiprocessing
简单来说遇到 CPU 密集型计算使用 multiprocessing, 相当于同时开启两个程序一起运行; 遇到 I/O 密集型计算还是可以使用 threading
线程锁
代码在 https://c.runoob.com/compile/9/ 或 https://www.bejson.com/runcode/python3/ 进行测试
- 由于在多线程中, 所有线程共享一个变量, 当程序在运行一半时释放 GIl 锁, 可能导致出现数据混乱问题
1 | import threading |
- 使用互斥锁 (Lock)、递归锁 (RLock) 都可以避免这种情况发生
互斥锁 Lock
- 使用
lock_obj = threading.Lock()实例化一个互斥锁 (Mutual exclusion, Mutex) 对象 使用 lock_obj.acquire()可以锁定当前线程, 锁定线程若不解锁, 则不会进入下一个线程- 使用
lock_obj.release()释放线程锁, 释放线程锁后可以执行下一个线程 - 在操作数据前锁定线程, 在操作数据完后释放线程锁, 可以有效避免数据混乱的问题
1 | import threading |
Lock的互斥锁不支持嵌套结构, 假如在一个互斥锁锁内部再嵌套一个互斥锁, 可能造成死锁程序无法继续运行
递归锁 RLock
- RLock 类的用法和 Lock 一样, 但是 RLock 支持嵌套结构, 可以在一个线程中上多个 RLock
- 只有当一个线程中所有的
RLock都被release, 后续的线程才能继续执行
信号量 Semaphore
- 互斥锁和递归锁只允许一个线程修改数据, 而 Semaphore 最多可以允许 5 个线程同时修改数据
- 使用
sem_obj = threading.BoundedSemaphore(信号量数量)实例化一个信号量对象 - 在线程中使用
sem_obj.acquire()锁定当前线程 - 在线程中使用
sem_obj.release()释放锁
1 | import threading |
2-3 事件 Event
- 事件主要用于控制其他线程的执行, 事件是一个简单的线程同步对象
- 使用
event_obj = threading.Event()定义一个事件对象 - 使用
event_obj.wait()监听 Flag 状态 - 全局共享一个 Flag, 当 Flag 值为
Flase时event.wait()就会阻塞, 反之则不阻塞 - 使用
evene_obj.set()设置 Flag 为True - 使用
event_obj.clear()设置 Flag 为False - 使用
event_obj.is_set()判断 Flag 状态为 True 或 False
1 | import threading |
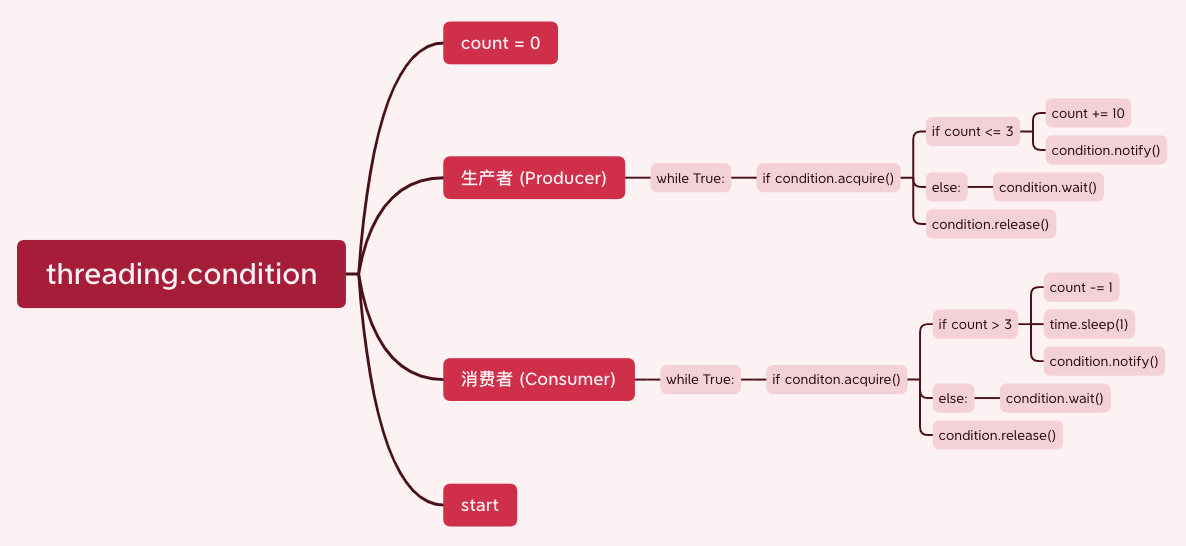
2-4 条件 Condition
Condition被称为条件变量,除了提供与
Lock类似的acquire和release方法外,还提供了wait和notify方法使用
cond_obj = threading.Conditon()实例化一个条件对象首先由一个线程使用
cond_obj.acquire()并且判断一个条件变量- 如果条件不满足则
cond_obj.wait()进入状态 - 如果条件满足, 使用
cond_obj,notify()通知其他方法, 其他处于wait状态的线程收到通知后会重新判断条件
- 如果条件不满足则
使用
while True条件循环语句不断循环这一步骤, 实现不同线程通信当调用
wait方法时, 线程会释放 Condition 内部的锁使线程进入堵塞 (blocked) 状态, 同时在 waiting 池中记录这个线程, 当调用notify方法时, Condition 对象会从 waiting 池中挑选一个线程, 通知其调用acquire方法尝试获取到锁Condition 对象的构造函数可以接受一个 Lock/RLock 对象作为参数, 如果没有指定, 则 Conditon 对象会在内部创建一个 RLock
Conditon 对象还提供了
notifyAll方法, 可以通知 waiting 池中所有的线程尝试acquire内部锁处于 waiting 状态的线程只能通过
notify方法唤醒, 可能导致某些线程永远处于等待状态, 使用notifyAll可以避免这种情况
1 | import threading |
Reference:
2-5 定时器 Timer
- 定时器 Timer 指定 n 秒后再执行操作
- 定义线程对象时直接使用
t_obj = threading.Timer(时间/秒, 函数名称)来定义定时器线程对象
1 | import threading |
3、多进程 multiprocessing 模块
3-1 创建子进程
- 使用
import multiprocessing导入多进程模块 - 使用
process_obj = multiprocessing.Process(target=函数名称, args=(参数1, 参数2))实例化一个多进程对象 - 使用
process_obj.start()启动子进程 - 使用
process_obj.join()等待进程结束 - 由于启动多线程时是启动了一个新的 Python 进程, 需要将
process_obj.start()放入if __name__ == "__main__"条件判断语句内, 避免无限循环
1 | import multiprocessing |
3-2 进程间通信
Queue()
- 使用
from multiprocessing import Queue导入Queue模块 - 使用
queue_obj = Queue()实例化一个Queue对象 - 启动子进程时, 需要将
queue_obj作为参数传入 - 在进程中使用
queue_obj.put('数据')存入数据 - 在任何位置使用
queue_obj.get()获取Queue对象数据 - 更多 queue 对象方法参考 Queue对象 Python 3.10 文档
1 | from multiprocessing import Queue, Process |
Piep()
- Pipe 类似于 socket 模块, 主要用于数据传递而不是数据共享,
pipe()返回两个连个链接对象分别为管道的两端, 每个连接对象都有send()发送、recv()接受方法 - 使用
from multiprocess import Pipe导入 Pipe 模块 - 使用
parent_conn, child_conn = Pipe()实例化子进程和父进程两端的通讯对象 - 使用
conn.send(obj)发送一个对象到连接的另一端 - 接收端使用
conn.recv()接受另一方发送的数据, 该方法会阻塞直到收到对象
1 | from multiprocessing import Process, Pipe |
3-3 Manager 管理线程
- 通过 Manager 可实现进程数据共享, Manager() 返回一个 manager 对象通过一个服务进程, 来使其他通过进程通过代理方式操作对象
- manager 支持
list、dict、Namespace、Lock、RLock、Semaphore、BoundedSemaphore、Condition、Event、Barrier、Queue、Value和Array - 使用
from multiprocessing import Manager导入 Manager 模块 - 使用
with Manager() as manager实例化一个 manager server 对象 - 使用
manager_obj = manager.list()创建一个 manager 列表对象 manager_obj需要作为参数传入子进程- 子进程可以直接操作
manager_obj
1 | from multiprocessing import Process, Manager |
3-4 进程锁 (进程同步)
- 类似线程锁, 锁定当前进程后其他进程无法继续运行, 主要用于保证输出在同一屏幕而会两行合并为一行
- 使用
lock = multiprocessing.Lock()实例化一个线程锁对象 - 使用
lock.acquire()锁定一个线程 - 使用
lock.release()释放一个线程
3-5 进程池
- 由于进程间切换可能导致占用大量内存空间, 为防止这种情况可以使用进程池
- 使用
from multiprocessing import Pool导入进程池模块 - 使用
pool = Pool(数量)实例化 n 个进程池对象 (允许同时放入 5 个进程) - 使用
pool.apply(func=函数名称, args=(参数1, ))同步 (串行) 执行 n 个线程 - 使用
pool.apply_async(func=函数名称, args=(参数1, ))异步 (并行) 执行 n 个线程 - 使用
pool.close()等待所有进程结束后再关闭进程池 - 使用
pool.join()等待所有子进程执行完毕后再结束主进程 (需要放在pool.close()之后)
1 | from multiprocessing import Process, Pool |
4、协程
- 线程和进程是由程序处罚系统接口, 最后的执行者是系统, 它本质上操作系统提供的功能
- 协程的操作是程序员指定的, 在 Python 中拖过 yield, 人为的实现并发处理
- 协程的意义:
- 对于多线程应用, CPU 通过切片方式来切换线程间的执行, 现成切换时, 需要消耗时间
- 协程只使用一个线程, 分解一个线程为多个 “微县城” 在一个线程中规定某个代码块的执行顺序
- 协程应用场景:
- I/O 密集型任务时 (大量操作不需要使用到 CPU)
- 实现协程常用第三方模块 gevent 和 greenlet (gevent 是对 greenlet 的高级封装, 一般使用 gevent 即可)
4-1 greenlet
- greenlet 通过 switch 方法在不同任务间切换
- 使用
from greenlet import greenlet导入模块 - 使用
gr_obj = greenlet(函数名称)实例化 greenlet 对象 - 使用
gr_obj.switch()手动切换下一个对象
1 | from greenlet import greenlet |
1 | # Output |
4-2 gevent
- gevent 的代码封装度很高, 使用只需要了解基本方法
- 使用
import gevent导入模块 - 使用
gevent.joinall([gevent.spawn(函数, "参数")])通过jioinall将任务函数和参数进行统一调度
1 | import gevent |
1 | # Output |
补充说明:
- 全部完成后建议跟着 Python 并发编程实战,用多线程、多进程、多协程加速程序运行 巩固实战案例
- 相关文章: Python 并发编程实战,用多线程、多进程和多协程加速程序运行
Reference: