Python 并发编程实战,用多线程、多进程和多协程加速程序运行
2022-12-01 19:39:00
0x00 引言
Python 并发编程简介
- 为什么要引入并发编程
- 场景1: 普通爬虫需要花费长时间的任务, 通过并发编程可以减少花费时间
- 场景2: APP 应用, 后台有大部分请求资源, 使用异步并发可以降低延迟
- 引入并发, 提升程序运行速度
- 学习掌握并发编程技术, 是程序员不可缺少的技能
- 有哪些程序提速的方法
- 可以通过四种方式提升程序运行速度: 单线程串行(不加改造的程序)、多线程并发(threading)、多CPU并行(multiprocessing)、多机器并行 (hadoop/hive/spark)
- 本节课程不会介绍多机器并行方式, 主要使用 threading、multiprocessing
- Python对并发编程的支持
- 多线程: threading, 利用 CPU 和 IO 可以同时执行的原理, 让 CPU 不会干巴巴等待 IO 完成
- 多进程: multiprocessing, 利用多核心 CPu 的能力, 真正的并行执行任务
- 异步 IO: asyncio, 在单线程利用 CPU 和 IO 同时执行的原理, 实现函数异步执行
- 使用 Lock 对资源枷锁, 防止冲突访问
- 使用 Queue 实现不同进程/现成间的数据通信, 实现生产者-消费者模式
- 使用线程池 Pool/进程池 Pool, 简化线程/进程的任务提交、等待结束、获取结果
- 使用 subprocess 启动外部程序的进程, 并进行输入输出交互
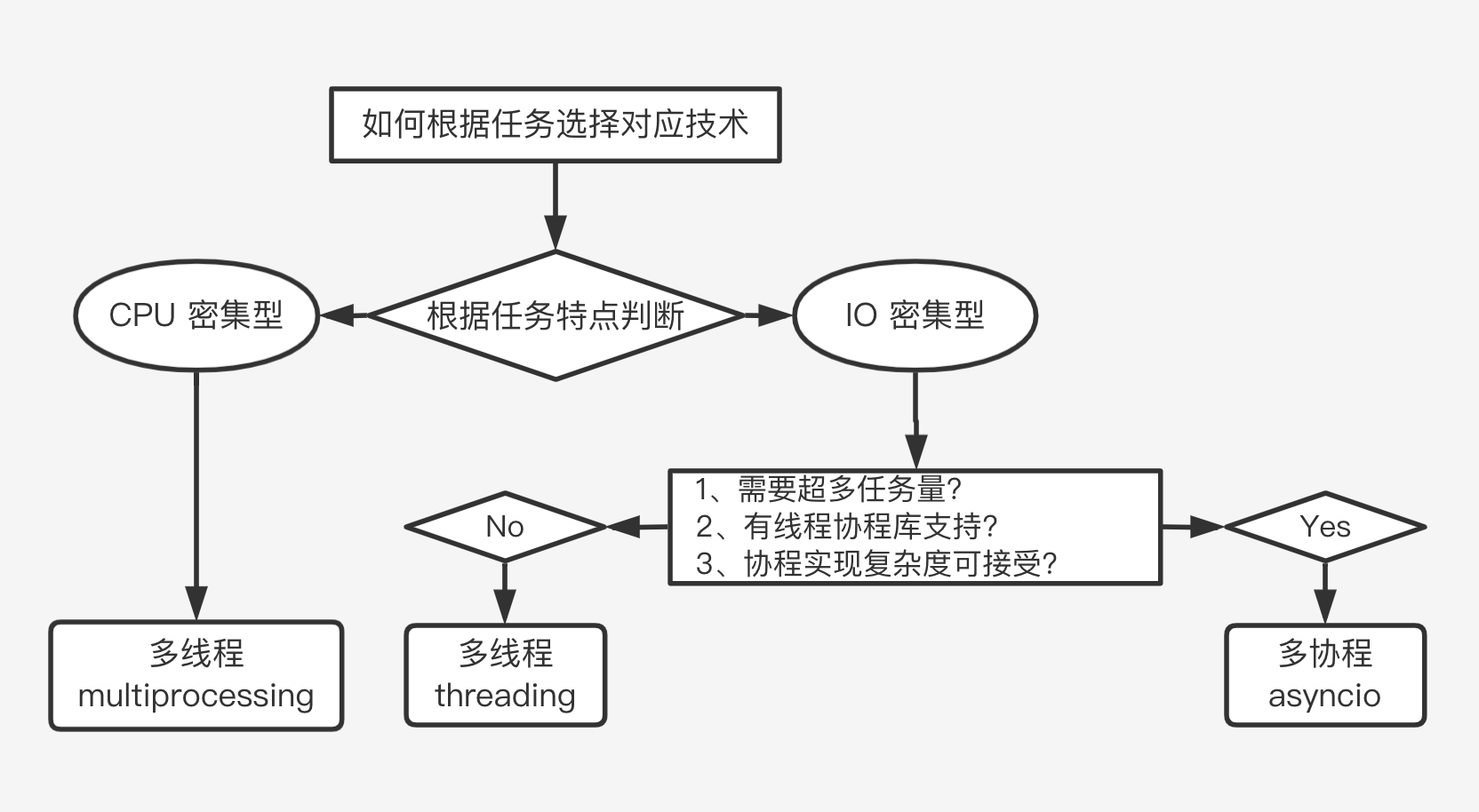
怎样选择多线程、多进程和多协程
- 什么是 CPU 密集型计算、IO 密集型计算?
- CPU-bound (CPU 密集型)
- 程序运行的速度受到 CPU 的限制
- CPU 密集型也叫计算密集型, 是指 I/O 在很的短时间内就可以完成, CPU 需要大量的计算和处理, 特点是 CPU 占用率相当高
- 例如: 压缩解压缩、加密解密、正则表达式搜索
- I/O-bound (IO 密集型)
- 程序运行的速度受到 I/O 的限制
- IO 密集型是指系统运作大部分的情况下是 CPU 在等待 I/O (硬盘/内存) 的读/写操作, CPU 实际占用率较低
- 例如: 文件处理程序、网络爬虫程序、读写数据库程序
- CPU-bound (CPU 密集型)
- 多线程、多进程、多协程的对比
- 多进程 Process (multiprocessing)、多线程 Thread (threading)、多协程 Coroutine (asyncio)
- 一个进程中, 可以启动 N 个线程、一个线程中, 可以启动 N 个协程
- 多线程 Thread
- 相比进程, 更轻量级, 占用资源少, 但在 Python 中多线程只能并发执行, 不能利用多 CPU (GIL 锁限制)
- 相比协程, 启动数目有限制, 占用内存资源, 有线程切换开销
- 主要适用于 I/O 密集型计算、同时运行的任务数目要求不多
- 多进程 Process
- 可以利用多核 CPU 并行运算, 但占用资源最多, 可启动数目最少
- 主要适用于 CPU 密集型计算
- 多协程 Coroutine
- 内存开销最少, 启动协程数量最多, 缺点在于支持的库有限制, 如 requests 不支持协程, 需要使用 aiohttp 代替, 实现代码相对复杂
- 适用于 I/O 密集型计算、需要超多任务运行、拥有现成库支持的场景
GIL 全局解释器锁
相比 C/C++/Java, Python 确实慢, 在一些特殊场景下, Python 比 C++ 慢 100~200 倍
由于速度慢的原因, 很多公司的基础架构代码仍然在使用 C/C++ 开发, 比如各大公司阿里、腾讯、快手的推荐引擎、搜索引擎、存储引擎等对性能要求高的模块
Python 速度慢的原因:
- Python 是动态类型语言, 不像 C/Java 需要编译后再执行, 而 Python 需要边解释边执行, Python 中的变量可以是数字也可以是字符, 同样在程序运行时, 需要不断检查变量的类型
- Python 存在 GIL 锁, 无法利用多核 CPU 并发执行
全局解释器锁 (Global Interpreter Lock, GIL)
- GIL 是计算机程序设计语言解释器用于同步的一种机制, 它使得任何时刻仅有一个线程在执行。即使在多核心处理器上, 使用 GIL 的解释器也只允许统一时间执行一个进程
- With the GIL, you get cooperative multitasking
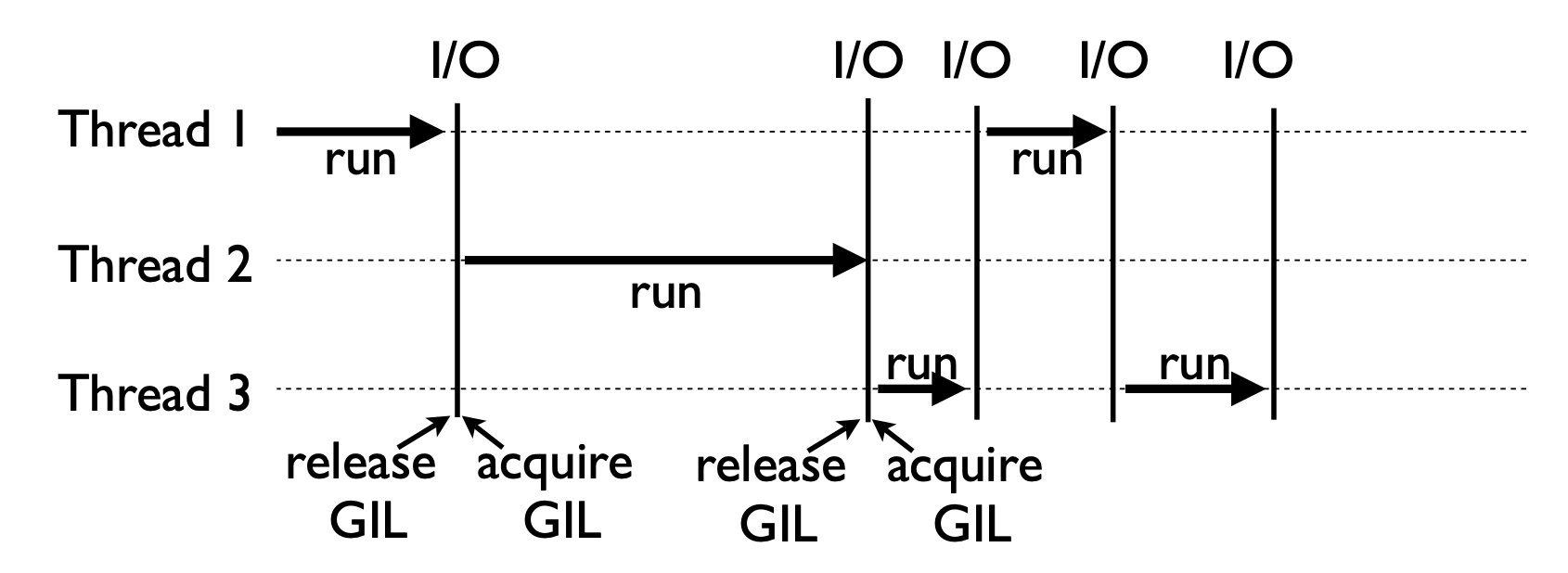
- When a thread is running, it holds the GIL
- GIL released on I/O (read,write,send,recv,etc.)
为何会有 GIL 解释器锁
- Python 设计的初期, 为了规避并发问题引入了 GIL, 而到现在因为大部分都库都依赖于 GIL 而运行, 现在想去除而又去不掉了
- GIL 主要存在的目的是为解决线程之间数据完整性和状态同步的问题, Python 中的对象管理, 是使用引用计数器进行的, 引用数为 0 则释放对象
怎样规避 GIL 带来的限制
多线程 threading 机制仍然是有用的, 用于 IO 密集型计算
- 在 I/O (read, write, send, recv, etc.) 期间, 线程会释放 GIL, 实现 CPU 和 IO 的并行, 因此在多线程用于 IO 密集型计算仍然可以大幅提升速度
- 但是多线程用于 CPU 密集型计算时, 只会更加拖慢速度
使用 multiprocessing 的多进程机制实现并行计算、利用多核 CPU 优势, 为了应对 GIL 的问题, Python 提供了 multiprocessing
0x01 利用多线程加速爬虫程序
Python 创建多线程的方式
- 首先准备任意一个函数
- 使用
import threading导入多线程模块 - 使用
t = threading.Thread(target=函数名称, args=(参数,))实例化一个线程对象 - 使用
t.strat()启动这个线程, 使用t.join()等待这个线程结束
1 | import threading |
单线程爬虫 VS 多线程爬虫速度对比
- 首先创建一个
craw()函数, 调用requests模块, 向页面发送请求并返回 url 和页面长度 - 使用 for 循环结构依次调用
craw()函数, 实现单线程调用, 并计算运行时间 - 使用
threads变量存储线程对象, 并依此添加所有 url, 通过 for 循环所有线程对象启动和终止
1 | import requests |
1 | # 程序运行结果 |
0x02 生产者消费者模式多线程爬虫
Pipeline 技术架构和生产者消费者模型
- 多组件的 Pipeline 技术架构
- 复杂的事情不会一下子做完, 而是分很多中间步骤一步步完成
- 比如说一个程序从输入数据到输出数据, 中间会经过多个处理器 (Processor), 每个处理器是一个处理模块, 这种将数据通过多个模块来处理的技术架构叫做 Pipeline 架构
- 生产者消费者模式就是典型的 Pipeline 架构, 生产者生产数据后, 会传递给消费者来消费数据
- 生产者传入的数据作为生产原料, 消费者输出的内容作为输出数据
- 生产者消费者爬虫的架构
- 生产者消费者架构相当于内部有两个 Processor
- 第一个 Processor 获取待爬取的 URL 进行网页的下载, 将下载好的内容放进一个 “网页队列”
- 第二个 Processor 消费 “网页队列” 中的数据进行解析, 并且把解析的结果进行存储
- Python 创建线程队列的方式
- 使用 queue.Queue 可以用于多线程之间的、线程安全的数据通信
- 使用
import queue导入队列类库 - 使用
q = queueQueue()创建队列对象 - 使用
q.put(item)添加元素- 当队列元素已满时会发生阻塞
- 使用
q.get()获取元素- 当队列元素为空时会发生阻塞
- 使用
q.qsize()查看元素大小 - 使用
q.empty()判断队列是否为空 - 使用
q.full()判断队列是否已满
代码编写实现生产者消费者爬虫
- 先创建两个函数,
craw()用于获取页面 html 结果,parse()用于提取页面元素 - 使用
url_queue = queue.Queue()创建一个 url 队列的对象 - 使用
html_queue = queue.Queue()创建一个 html 队列的对象 - 再创建两个队列函数, 无限循环并一直等待 queue 队列
get或put传入或输出数据do_craw()线程通过url_queue.get()获取 url, 并将 url 传入craw()函数获取 html 内容, 再通过html_queue.put(html)将获取到的 html 内容传入html_queue队列do_parse()线程通过html_queue.get()获取do_craw()传入的 html 内容, 调用parse()函数解析, 并将解析的结果直接输出
- 通过
for循环结构将 url 全部put进入url_queue队列 - 再通过
for循环结构创建并启动指向do_craw()和do_parse()函数的多个线程
1 | import threading |
0x03 线程安全问题以及 Lock 解决方案
线程安全概念介绍
- 线程安全指某个函数、函数库在多线程环境中被调用时, 能够正确地处理多个线程之间的共享变量, 使程序功能正确完成。
- 由于线程的执行随时会切换, 就造成了不可预料的结果, 出现线程不安全
Lock 用于解决线程安全问题
- 使用
lock = threading.Lock()实例化一个线程锁对象 - 使用
lock.acquire()锁定线程, 再使用lock.release()释放线程锁, 或是在执行代码前使用上下文管理with lock:后续执行的代码都将被设置线程锁, with 代码块内的代码运行结束后, 线程锁自动释放
1 | import threading |
0x04 好用的线程池 ThreadPoolExecutor
线程池的生命周期和原理
- 线程的生命周期状态包括新建、就绪、运行、终止和阻塞
- 新建的线程通过 start 进入就绪状态, 此时线程并没有真正开始运行, 线程的运行需要系统进行调度
- 通过系统调度线程真正进入运行状态
- 运行中的线程可能会因为失去 CPU 资源, 重新进入就绪状态
- 也有可能会因为遇到 sleep 或 io 进入阻塞状态, 等到 sleep 或 io 完成后重新进入就绪状态
- 当线程运行完毕后线程进入终止状态
- 线程池的原理
- 新建线程系统时需要分配资源, 终止线程系统需要回收资源, 当系统中存在大量线程需要使用时, 会频繁的新建和终止线程, 会产生大量的时间开销和线程开销
- 如果可以重用线程, 则可以减去新建/终止的开销
- 使用线程池时, 当有新的任务创建后, 新的任务会被放入任务队列中, 线程池会依次调用线程队列中的任务, 放入线程池中执行, 完成后会取下一个任务继续执行, 当所有线程都执行完成后, 线程池并不会销毁, 而是等待下一个任务的到来
- 线程池的好处
- 提升性能: 因为减去了大量新建、终止线程的开销, 重用了线程资源
- 适用场景: 适合处理突发性大量请求或是需要大量线程完成任务、但实际任务处理时间较短
- 防御功能: 能有效避免系统因为创建线程过多, 而导致系统负荷过大响应变慢等问题
- 代码优势: 使用线程池的语法比自己新建线程执行线程更加简洁
ThreadPoolExecutor 的使用语法
- 使用
from concurrent.futures import ThreadPoolExecutor, as_completed导入模块 - 使用
with ThreadPoolExecutor() as pool:实例化一个线程池对象- 在 with 语句内使用
results = pool.map(函数名称, 参数列表)将每一个参数作用于线程池对象并获得返回结果 - 也可以使用列表推导式
futures = [pool.submit(函数名称, 参数) for 参数 in 参数列表]的方式通过pool.submit给线程池传入对象 - futures 返回对象的结果存储在
futures.results()内, 两种遍历方式如下 (使用 as_completed 时返回的顺序是不一定的, 而普通的遍历是依次返回)
- 在 with 语句内使用
1 | for feture in futures: |
使用线程池改造爬虫程序
- craw 线程池
- 使用
with concurrent.futures.ThreadPoolExecutor() as pool:创建线程池对象 - 使用
pool.map(craw, urls)将 urls 列表中每一个元素都传入 craw 函数, 作用与线程池 - 使用
zip(urls, htmls)将 urls 的元素依次与 htmls 的元素对应生成一个 zip 对象 (url 对应 htmls) - 通过
for循环遍历输出 url 对应的 html 页面长度信息 (在程序内已经存在 htmls 列表)
- 使用
- parse 线程池
- 使用
with concurrent.futures.ThreadPoolExecutor() as pool:创建线程池对象 - 使用
for循环依次遍历 url 和 html 内容 - 使用
pool.submit(parse, html)将 html 内容传入 parse 函数进行解析 - 创建一个
futures字典用来存储 url 以及对应提取后的内容 - 使用
futures[future] = url为字典填入 url 和提取后的内容 - 最后通过 for 循环遍历
futures.items()字典的 url 和提取后的内容 - (使用 as_completed 遍历元素时, 不可以同时使用
items()函数, url 需要在循环结构内再次进行赋值)
- 使用
1 | import requests |
0x05 在 Web 服务中使用线程池加速
#Skip-Temporarily
- Web 服务的架构以及特点
- 使用线程池 ThreadPoolExecutor 加速
- 代码用 Flask 实现 Web 服务并实现加速
0x06 使用多进程 multiprocessing 加速程序运行
为何有了多线程还需要多进程
- 如果遇到了 CPU 密集型计算, 多线程反而会降低执行速度
- 虽然有全局解释器锁 GIL, 但因为有 IO 的存在, 多线程依然可以加速运行
- CPU 密集型计算, 线程的自动切换反而变成了负担, 多线程甚至会减慢程序运行速度
- multiprocessing 模块就是 Python 为了解决 GIL 缺陷引入的一个模块, 原理是用多进程在多 CPU 上并行执行
- 多进程和多线程的语法几乎完全相同, 如下图所示

单线程、多线程、多进程对比 CPU 密集计算速度
1 | import math |
1 | # 程序运行结果 |
0x07 在 Flask 服务中使用进程池加速
#Skip-Temporarily
0x08 Python 异步 IO 实现并发爬虫
协程的基本概念
- 协程: 在单线程内实现并发
- 核心原理在于用一个超级循环 (其实就是 while true) 循环, 配合 IO 多路复用 (IO 时 CPU 可以做其他事)
- 在一个线程进行中的步骤为 CPU、等待 IO、CPU, 使用协程可以在中途等待 IO 完成后, 直接进入下一个任务的第一个 CPU 计算状态, 而不必等待结果返回后再进入下一个任务
Python 异步 IO 库 asyncio 使用
- 使用
import asyncio导入异步 IO 库 - 使用
async def 函数名称(参数)定义协程函数 - 携程函数内使用
await 属性名称定义代码块, 不会等待, 而是直接切换到下一个任务 - 使用
loop = asyncio.get_event_loop()获取事件循环 (超级循环) - 使用
tasks = [loop.create_task(函数名称(参数)) for url in urls]创建 task 列表 - 使用
loop.run_until_complete(asyncio.wait(task))执行 task 列表 - 使用协程需要对应的库支持异步 IO 特性, 其中 requests 不支持异步, 而 aiohttp 支持
1 | import asyncio |
0x09 在异步 IO 中使用信号量控制爬虫并发度
信号量 Semaphore
- 信号量 (Semaphore) 又称为信号量, 旗语言
- 是一个同步对象, 用于保持在 0 至最大值之间的一个计数器
- 当线程完成一次对该 semaphore 对象的等待 (wait) 时, 该计数值减一
- 当线程完成一次对 semaphore 对象的释放 (release) 时, 计数值减一
- 当计数值为 0, 则线程等待该 semaphore 对象不再能成功直至该 semaphore 对象变成 signaled 状态
- semaphore 对象的计数值大于 0, 为 signaled 状态, 计数值等于 0, 为 nonsignaled 状态
使用 Semaphore 模块控制并发度
- 使用
sem = asyncio.Semaphore(10)实例化一个信号量对象 - 使用
async with sem:语句块的代码都会遵循设置好的信号量运行 - 或是使用
await sem.acquire()锁定信号量, 再try:语句执行代码, 最后通过finally: sem.release()释放信号量限制
Reference: